
どうもこんにちは!
サバ缶(@tech_begin)です。
正規化とか第2正規形とか……
何のことだか、全く意味がわかんない!
IPA基本情報技術者試験などで多く出題される「正規化」について。
正直、わたし自身も理解が浅かったので休日を使って学び直してみました!
- 正規形の基礎
- 正規化のやり方
- 関数従属などの用語について
さっそく学んで行きましょう!
正規化とは
正規化とは、データベース上のデータの重複(冗長)をなくし、整合性の取れたデータベースを設計する手法です。
データベースの中身が整理されていないと、管理やデータの取得・更新・削除などが実行しにくくなります。
ちなみに正規化は「考え方・手法」であって、実際にデータベースを操作するわけではないので注意してくださいね。
正規化のメリット
正規化されたテーブルを「正規形」と呼びます。
この正規形になっているデータによって、どんなメリットがあるのか。それは以下の通りです。
- データの一貫性を維持することができる
- CRUD処理に伴うデータの不整合や喪失が防げる
- CRUD処理の効率的なデータアクセスが可能になる
正規化のデメリット
「1つのテーブルに同じデータを持たない」という考えのもと設計していきます。
正規化を突き詰めていけばいくほど、データは整理され、テーブルの数が増えていきます。
システムにとって扱いやすい状態になればなるほど、私たち人間からすると少し煩雑な設計になってしまうことがデメリットです。
参画したてのプロジェクトとかだと、
データベースの構造の理解に時間がかかることも多々あります……
正規化の段階と種類
正規化の具体的な手順に入るまえに、全体像をおさえておきましょう。
基本情報などの勉強をしている方は「第3正規形」までをよく目にすると思います。
わたしも調べてみるまで知らなかったのですが、正規化は6段階まであります。
- 非正規形
- 第1正規形
- 第2正規形
- 第3正規形
- ボイスコッド正規形
- 第4正規形
- 第5正規形
こんなに沢山ありつつも、実際には第3正規形までしか使われないことが多いようです。
気になる方は調べてみると面白いと思います!ぜひ深掘りしてみてください。
ここでは「第3正規形」までに絞って解説していきますね。
第3正規化までの流れ
さて次は、第3正規化までの流れを紹介します。
この段階では「意味わからん」という状態でも大丈夫です👍
あとで詳しく図解で解説していきます。
- 非正規形
- 繰り返し項目があり、データベースに格納できない状態
- 第1正規形
- 繰り返し項目をなくした状態
- 第2正規形
- 主キーの一部によって、一意に決まる属性を別の表に移した状態
- 第3正規形
- 主キー以外の属性によって、一意に決まる属性を別の表に移した状態
言葉だけ見てもよくわからないと思いますので、ここからは図を交えて解説していきます!
正規化の手順を解説
まずはイメージしやすいように、あなたはカレー屋さんと思ってください(無理矢理)

店主(あなた↑)は、契約している農家さんや仕入れたものを手書きで管理しています。
……とイメージしてください。
非正規形
非正規形とは、1行(1レコード)の中に複数の繰り返し項目が存在するようなテーブルの状態を指します。
このような状態だと、データベースに登録することができません。
なぜかというと、データベースのテーブルは「1つのレコード単位」でデータが格納されるため、図のようにまとまった状態だと扱うことができないからです。
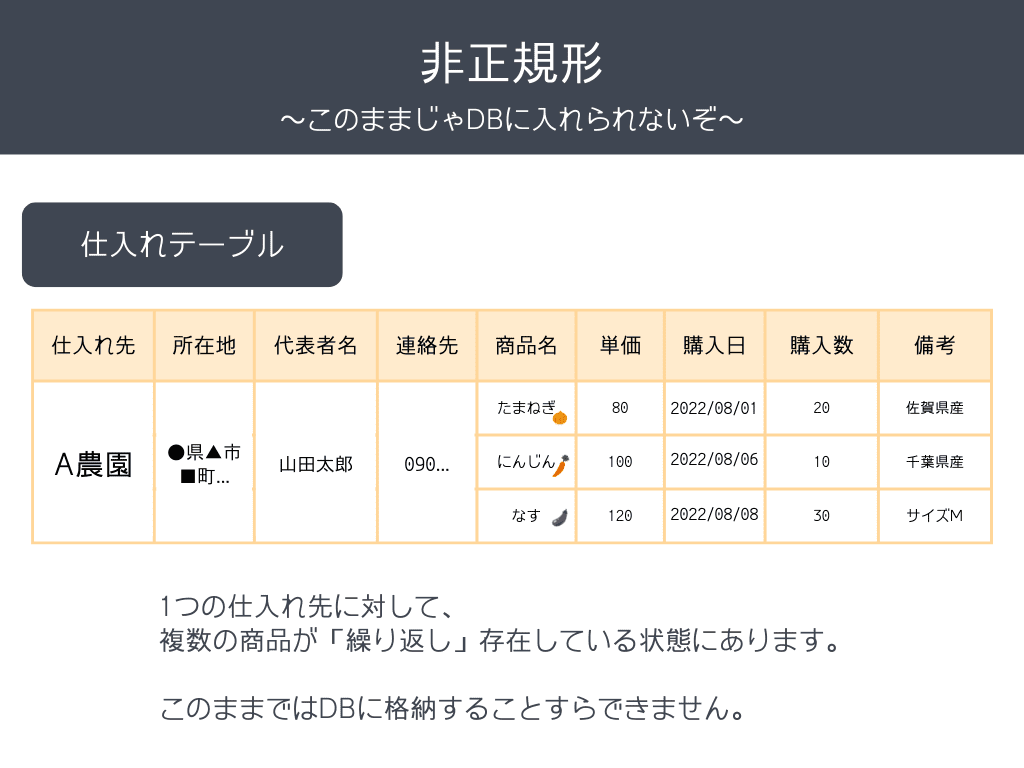
A農園に対して、複数の商品や購入日などがありますね。これを「繰り返し項目」と呼びます。
- 繰り返し項目があり、データベースに登録できない
第1正規形
データベースにデータを格納するために、繰り返し項目をそれぞれ独立させます。
1レコードのなかにあった繰り返し項目を独立させた状態が、図のような状態です。
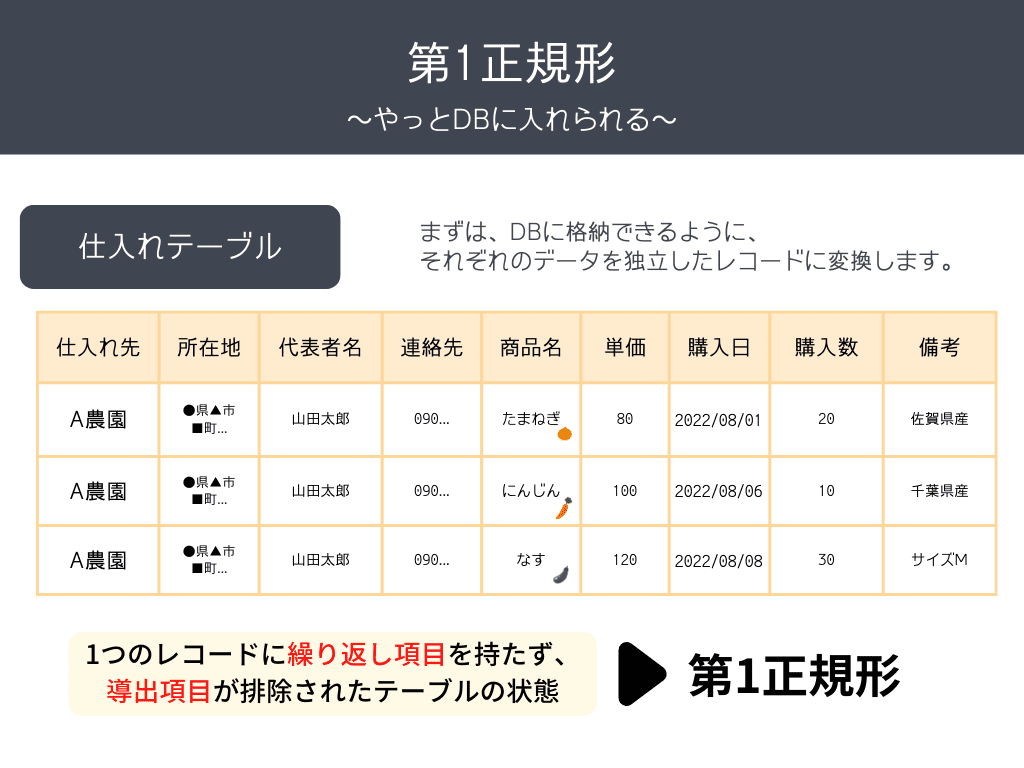
ここまでは比較的かんたんかと思います。
- 1つのレコードに繰り返し項目がない
- 導出項目が排除されている
上記しれーっと書いていますが、
導出項目とは、カラムの情報から算出することができる情報のことです。
例えば(今回は割愛していますが)「在庫数」というカラムがあったとしましょう。
「在庫数」は、「購入数」を合計することで算出することが可能です。
したがって、第1正規形の段階でこの導出項目は排除されます(することができます)。
第2正規形
第1正規形で、データベースに格納することができる状態にまでなりました。
しかし、まだまだデータの管理において不十分な点が多いです。
- ①新たな仕入先と契約した場合、何か入荷するまで相手の情報を登録できない(管理できない)
- そうなると、代表者の管理がしにくい!
- ②仕入先の代表者名が変わったら、複数のレコードを更新しなければならない
- サーバの負荷、不整合が起きる恐れも
なぜ①と②の事象が起きてしまうのか?
それは、仕入先の情報、商品の情報、入荷の履歴といった『本来、独立独立していなければならない情報』が1つのレコードにまとまっていることが原因です。
それでは、この原因を解消させていきましょう!
ここから先は『関数従属』という用語を使っていきます。
もし理解が浅い場合は、関数従属について知っておきましょう!
関数従属とは、ある値が決まると別のある値も決まる関係性のことを言います。
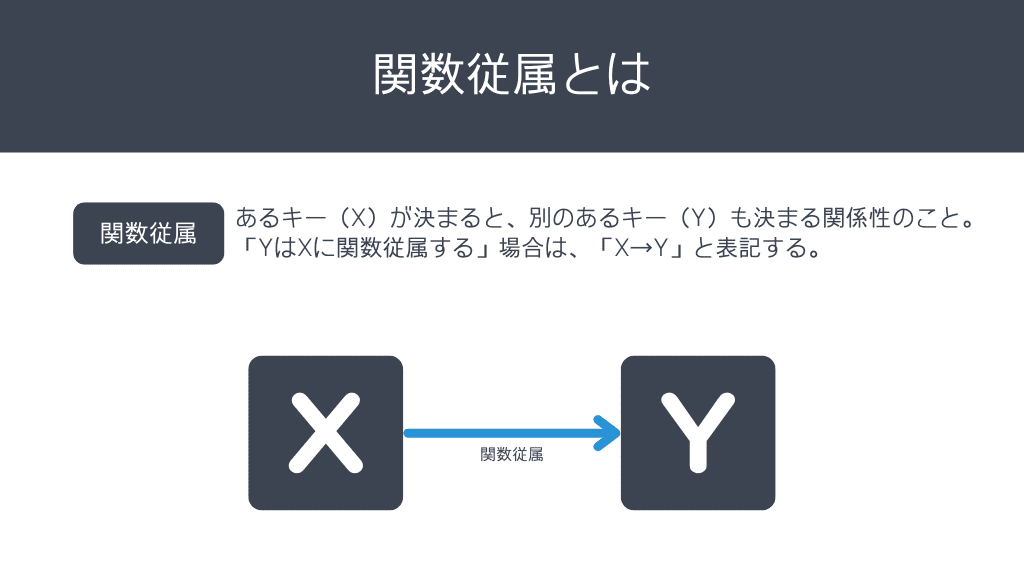
この関係性を、現在の仕入れ先テーブルで見つけていきましょう。
下の図を見てみると、関数従属するキーがあることがわかります。
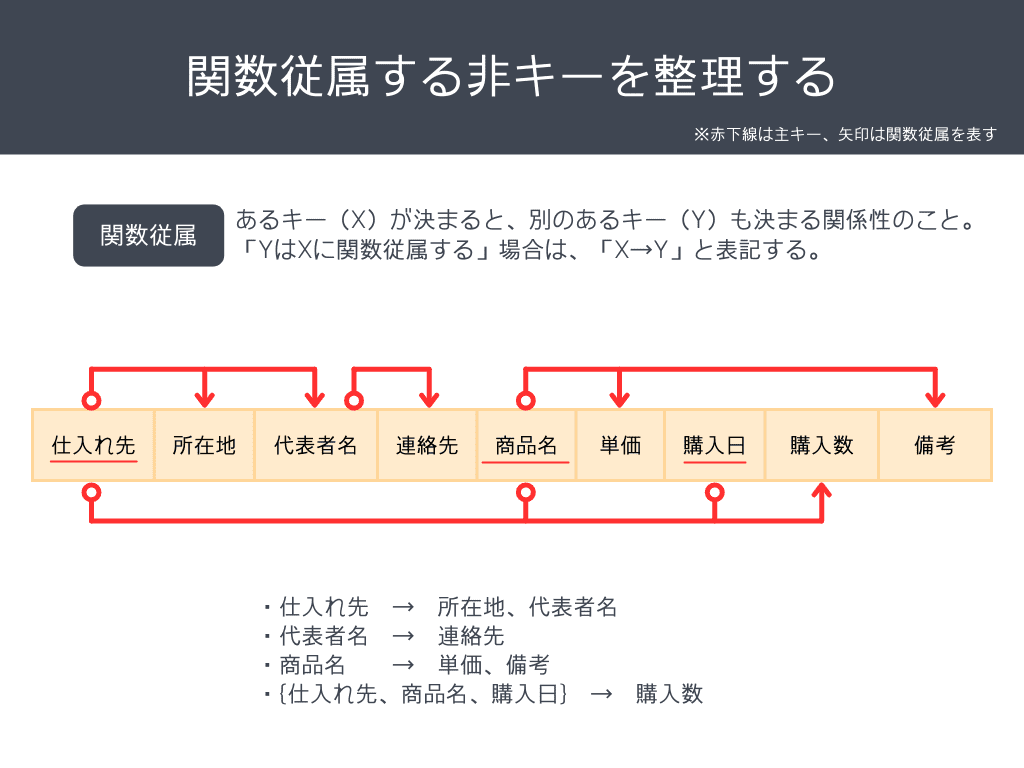
整理すると、4つの関数従属があります。
- 仕入れ先 → 所在地、代表者名
- 代表者名 → 連絡先
- 商品名 → 単価、備考
- 仕入れ先、商品名、購入日 → 購入数
矢印で書いているので分かりにくいですが、言い換えると「仕入れ先が決まると、所在地と代表者がわかる」といえます。その他も同様ですね。
それでは1つ1つ分解していきますよ!
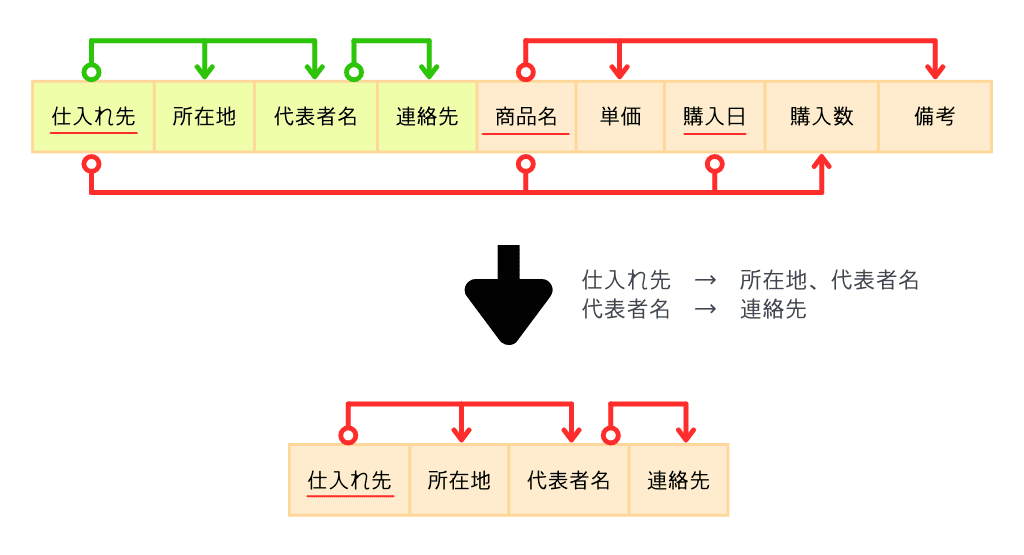
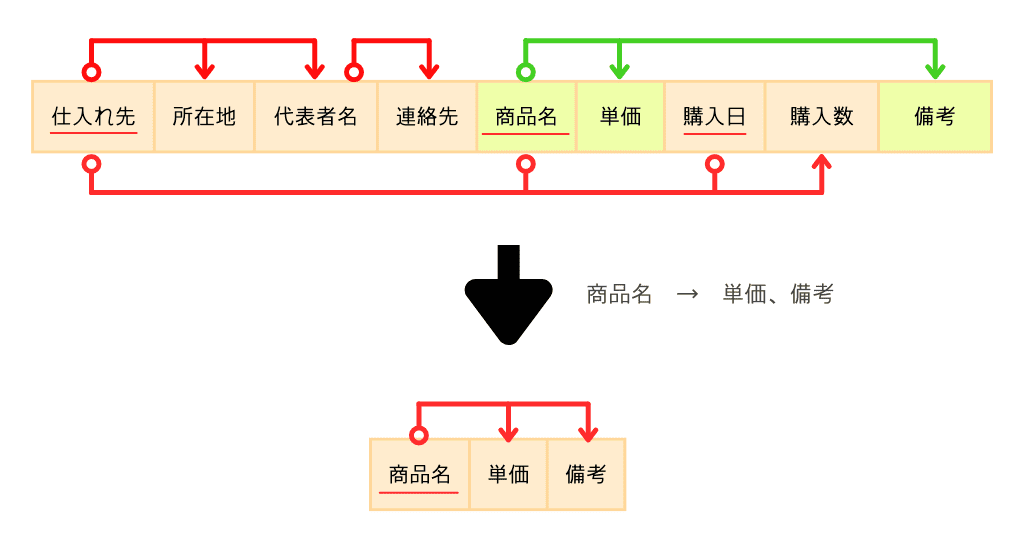
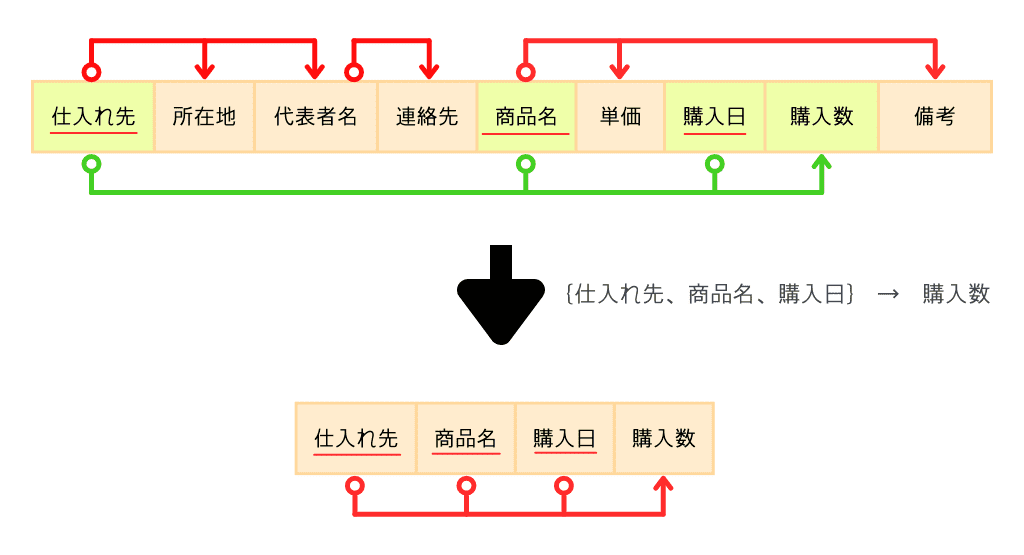
このように(非キー属性について)、主キーの一部の要素だけで決まるものがあれば別テーブルに分けていきます。
『主キーの一部の要素だけで決まるもの』を言い換えると『部分関数従属』といいます。
この部分関数従属を取り除くのが第2正規化、取り除かれた状態が第2正規形です。

- 部分関数従属を排除した(=完全関数従属を満たしている)状態
ちょっとここで閑話休題。補足情報を書いておきます。
少しややこしいので、読み飛ばしても全然大丈夫ですよ👌
さて、記事のはじめに『正規化はDBのテーブルを整理するための方法』だと説明しました。
その正規化を行なったことによって整理された形を「正規形」と呼びます。
つまり、上記の第2正規形は厳密にいうと
- 部分関数従属の排除をすること → 第2正規化
- 部分関数従属を排除すると完全関数従属を満たしている状態になる
- 完全関数従属を満たしている状態 → 第2正規形
このような関係性であると言えます。少しややこしいですが、意外と重要な部分でもあるので念のため補足として記しました。
さぁ、次で最後。第3正規形を学びましょう!
第3正規形
テーブルを分割したことで、だいぶ整理しやすくなりました。
しかし、これでもまだまだ不十分です。
もし「仕入れ先テーブル」の田中さんが、複数の農園を経営していたらどうでしょうか。
- ①代表者名の変更がある場合、仕入れ先テーブルにおいて複数のレコードを変更しなければならない
- ②連絡先の変更がある場合、仕入れ先テーブルにおいて該当の代表者全ての連絡先を変更しなければならない
このように、1つの修正のために複数のレコードを変更しなければならないことは避けなければなりません。
実際のサーバでは、数十万レコードもある場合は珍しくありません。多数のレコードを変更するとなるとDBサーバの負荷も高まってしまいます。
そこで「推移的関数従属」のキーを別テーブルに分けます。
ここから先は『推移的関数従属』という用語が重要になってきます。
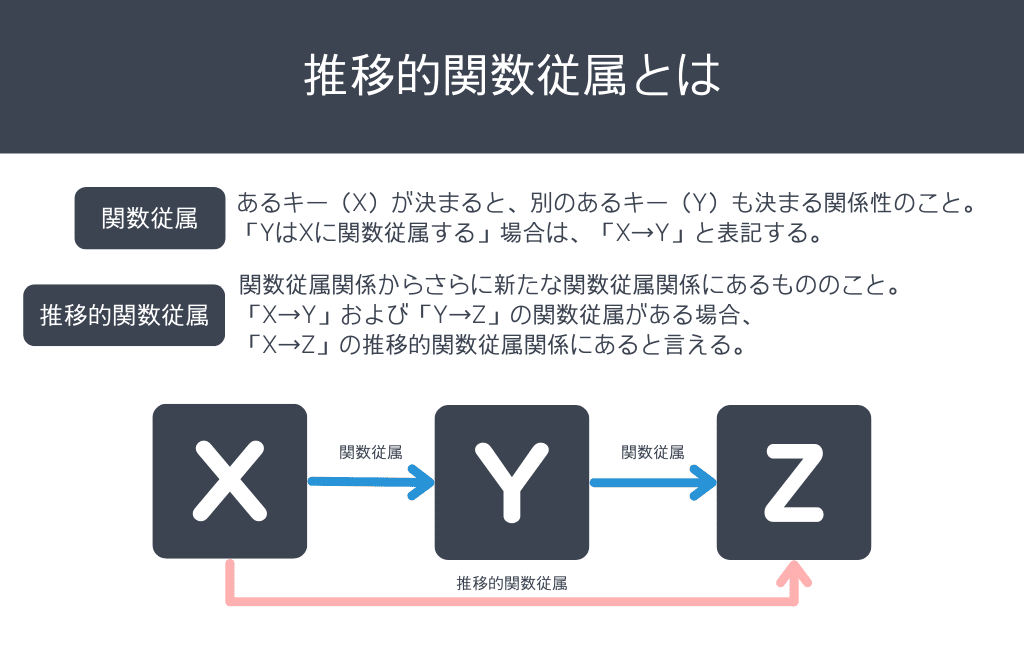
ここで『推移的関数従属』についておさらいしておきましょう!
関数従属とは、ある値が決まると別のある値も決まる関係性のことを言います。
推移的関数従属は、さらに次の関数従属関係があることです。
以下の図のように、X→Y→Zのそれぞれの関数従属関係がある場合、X→Zが推移的関数従属関係にあると言えます。
以下の図の通り、いったん第1正規形で確認してみましょう。
緑色のカラムが仕入れ先テーブルに該当します。
関数従属に該当するのは『仕入れ先→代表者名→連絡先』ですね。
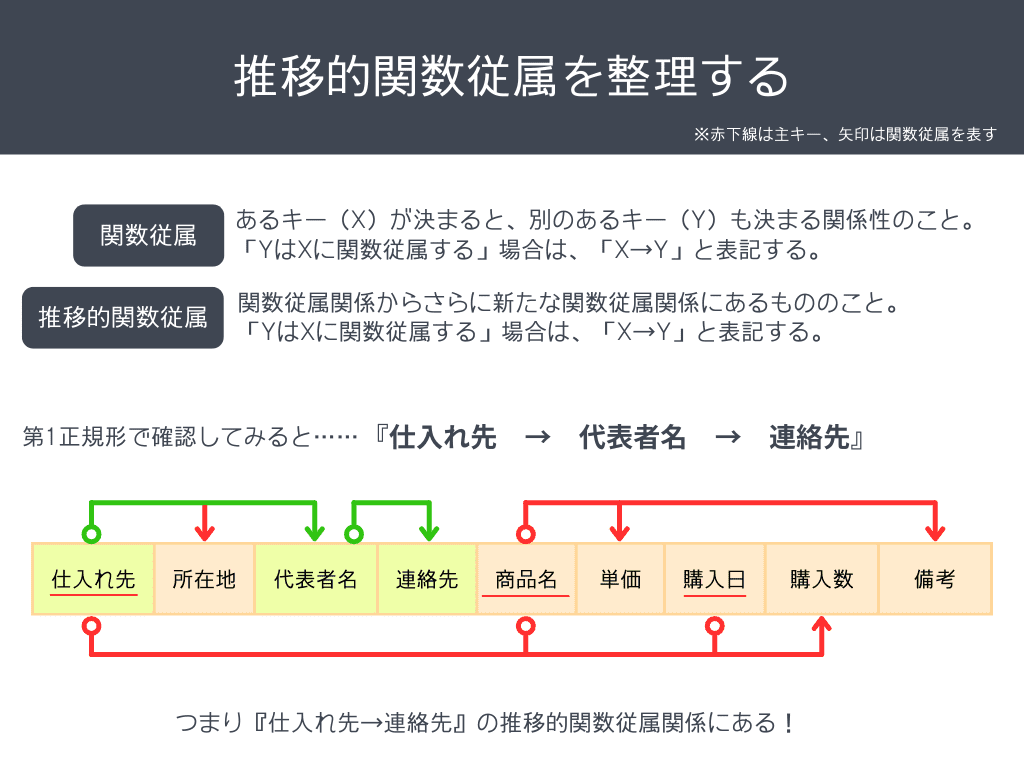
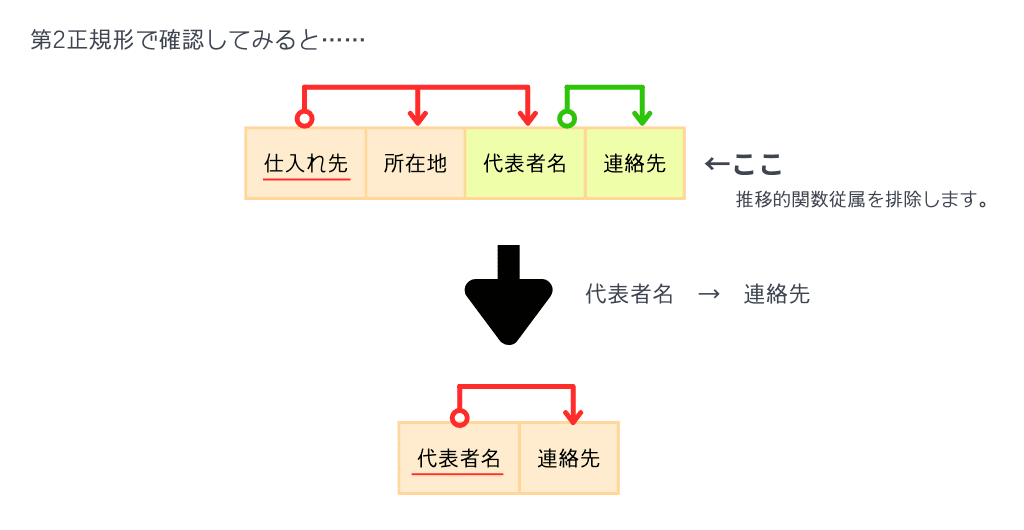
そして今、「仕入れ先テーブル」として分けているので、
上の図のように推移的関数従属を別テーブルに分けることができますね。
こうして推移的関数従属を排除することができました。

これで第3正規化まで行うことができました!🙌
お疲れ様でした。
正規化についてのまとめ
今回、図をまじえて第3正規化まで行いました!
- 非正規形
- 繰り返し項目があり、データベースに格納できない状態
- 第1正規形
- 繰り返し項目、導出項目をなくした状態
- 第2正規形
- 主キーの一部によって、一意に決まる属性を別の表に移した状態
- 部分関数従属を排除する
- 第3正規形
- 主キー以外の属性によって、一意に決まる属性を別の表に移した状態
- 推移的関数従属を排除する
「ここが違うよ〜」などのご指摘、「ここどういうこと?」という質問があればお気軽にTwitterでご連絡ください📨
【補足】Twitterで頂いたご指摘
logres_Fanさんより、ご指摘をいただきました。
より現場の状況に近い想定で、前提条件の設定をすべきでしたね🙏

